
取り込んだデータに重複情報がある場合、min関数やmax関数を使って1データのみ取り出すことがありますね。
select文で必要な情報のみを取り出せばいいのですが、そもそも重複データがいらない場合は削除してしまった方が後処理が早いです。
例
- アンケートを取得したが同じ人が複数回回答していて最新情報しか必要ではない。
- 来店情報を貯めているが、今回は直近の来店情報のみを後処理で利用したい。
目次
削除クエリーで一気に削除
DELETE T1.* FROM 来店履歴 AS T1 WHERE T1.[ID] Not In
(SELECT TOP 1 ID FROM 来店履歴 AS MAX1 WHERE MAX1.顧客名 = T1.顧客名 ORDER BY MAX1.来店日 DESC)
削除クエリーの解説
今回の例では、来店履歴のテーブルに以下のように1人の顧客に複数のデータがある状態を想定しています。
この情報の中から、直近以外のデータを削除するクエリーをご紹介しています。
| ID | 来店日 | 顧客名 |
|---|---|---|
| 1 | 2019/07/01 | 田中 太郎 |
| 2 | 2019/07/02 | 田中 太郎 |
| 3 | 2019/07/11 | 田中 太郎 |
| 4 | 2019/07/23 | 佐藤 花子 |
| 5 | 2019/08/01 | 佐藤 花子 |
イメージはこんな感じです。
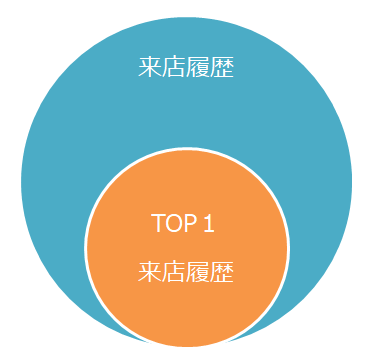
全ての来店履歴の中からTOP1の来店履歴以外のデータ(水色の部分)を削除します。
具体的には、来店履歴から「TOP1だけを抽出したTOP1来店履歴」に存在しないデータ(Not In)を削除するというものです。
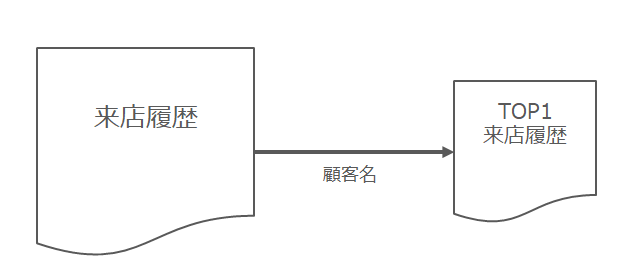
【SELECT TOP 1】文で来店日が最大の1データのみ取得します。
【ORDER BY MAX1.来店日 DESC】で来店日の降順でデータを取得することで直近の来店日がTOP1となります。
よって、初回来店日が欲しければDESC句を削除しましょう。
このクエリーを実行することで来店履歴テーブルのデータは以下のようになります。
| ID | 来店日 | 顧客名 |
|---|---|---|
| 3 | 2019/07/11 | 田中 太郎 |
| 5 | 2019/08/01 | 佐藤 花子 |









コメント